Experiment No: AI-
TITLE: - Implement
Tic-Tac-Toe or any multiplayer game minmax
algorithm
Problem Statement: - Implement Tic-Tac-Toe multiplayer game using AI technique &
MinMax algorithm (C++/Java)
Objective:
To study techniques
of Artificial Intelligence & MinMax algorithm
Requirements (Hw/Sw): PC, Netbeans IDE/Text Editor
(Linux)
Theory:-
Since the invention of computers or machines, their capability to
perform various tasks went on growing exponentially. Humans have developed the
power of computer systems in terms of their diverse working domains, their
increasing speed, and reducing size with respect to time.
A branch of Computer Science named Artificial Intelligence pursues
creating the computers or machines as intelligent as human beings.
1956->John McCarthy coined the term Artificial Intelligence.
Demonstration of the first running AI program at Carnegie Mellon University.
What is Artificial Intelligence?
According to the father of Artificial Intelligence, John McCarthy,
it is “The science and engineering of making intelligent machines,
especially intelligent computer programs”.
Artificial Intelligence is a way of making a computer, a
computer-controlled robot, or a software think intelligently, in the
similar manner the intelligent humans think.
AI is accomplished by studying how human brain thinks, and how
humans learn, decide, and work while trying to solve a problem, and then using
the outcomes of this study as a basis of developing intelligent software and
systems.
Philosophy of AI
While exploiting the power of the computer systems, the curiosity
of human, lead him to wonder, “Can a machine think and behave like
humans do?”
Thus, the development of AI started with the intention of creating
similar intelligence in machines that we find and regard high in humans.
Goals of AI
·
To Create Expert Systems − The systems which exhibit intelligent behavior, learn, demonstrate,
explain, and advice its users.
·
To Implement Human
Intelligence in Machines − Creating systems
that understand, think, learn, and behave like humans.
·
Programming Without and With AI
·
The programming without and with AI is different in following ways
−
Programming Without AI
|
Programming With AI
|
A computer program without AI can answer the specific questions
it is meant to solve.
|
A computer program with AI can answer the generic questions
it is meant to solve.
|
Modification in the program leads to change in its structure.
|
AI programs can absorb new modifications by putting highly
independent pieces of information together. Hence you can modify even a
minute piece of information of program without affecting its structure.
|
Modification is not quick and easy. It may lead to affecting the
program adversely.
|
Quick and Easy program modification.
|
Implementation
of Tic-Tac-Toe game
Rules of the Game
§
The game is to be
played between two people (in this program between HUMAN and COMPUTER).
§
One of the player
chooses ‘O’ and the other ‘X’ to mark their respective cells.
§
The game starts with
one of the players and the game ends when one of the players has one whole row/
column/ diagonal filled with his/her respective character (‘O’ or ‘X’).
§ If no one wins, then the
game is said to be draw.
§
Implementation
In our program the moves taken by the computer and the human are chosen
randomly. We use rand() function for this.
Winning Strategy
If both the players
play optimally then it is destined that you will never lose (“although the
match can still be drawn”). It doesn’t matter whether you play first or
second.In another ways – “ Two expert players will always draw ”.
Minimax
Algorithm in Game Theory
Minimax is a kind of backtracking algorithm that is used in decision
making and game theory to find the optimal move for a player, assuming that
your opponent also plays optimally. It is widely used in two player turn based
games such as Tic-Tac-Toe, Backgamon, Mancala, Chess, etc.
In Minimax the two players
are called maximizer and minimizer. The maximizer tries
to get the highest score possible while the minimizer tries
to get the lowest score possible while minimizer tries to do opposite.
Every board state has a value associated with it. In a given state
if the maximizer has upper hand then, the score of the board will tend to be
some positive value. If the minimizer has the upper hand in that board state
then it will tend to be some negative value. The values of the board are
calculated by some heuristics which are unique for every type of game.
Example:
Consider a game which has 4 final states and paths to reach final state are from
root to 4 leaves of a perfect binary tree as shown below. Assume you are the
maximizing player and you get the first chance to move, i.e., you are at root,
and your opponent at next level. Which move you would make as a maximizing player considering that
your opponent also plays optimally?
Since this is a backtracking based algorithm, it tries all possible
moves, then backtracks and makes a decision.
§
Maximizer goes LEFT
: It is now the minimizers turn. The minimizer now has a choice between 3 and
5. Being the minimizer it will definitely choose the least among both, that is
3
§
Maximizer goes RIGHT
: It is now the minimizers turn. The minimizer now has a choice between 2 and
9. He will choose 2 as it is the least among the two values.
Being the maximizer you would choose the larger value that is 3.
Hence the optimal move for the maximizer is to go LEFT and the optimal value is
3.
Now the game tree looks like below :
The above tree shows two possible scores when maximizer makes left
and right moves.
Evaluation Function
As seen in the above article, each leaf node had a value associated
with it. We had stored this value in an array. But in the real world when we
are creating a program to play Tic-Tac-Toe, Chess, Backgamon, etc. we need to
implement a function that calculates the value of the board depending on the
placement of pieces on the board. This function is often known as Evaluation Function. It is sometimes also called Heuristic Function.
The evaluation function is unique for every type of game. In this
post, evaluation function for the game Tic-Tac-Toe is discussed. The basic idea
behind the evaluation function is to give a high value for a board if maximizer‘s turn or a low value for the board if minimizer‘s turn.
For this scenario let us consider X as the maximizer and O as the minimizer.
Let us build our
evaluation function :
1.
If X wins on the board we give it a positive value of +10.
2.
If O wins on the board we give it a negative value of -10.
3.
If no one has won or the game results in a draw then we give a
value of +0.
We could have chosen
any positive / negative value other than 10. For the sake of simplicity we
chose 10 for the sake of simplicity we shall use lower case ‘x’ and lower case
‘o’ to represent the players and an underscore ‘_’ to represent a blank space
on the board.
Minimax
Algorithm in Game Theory | (Tic-Tac-Toe AI – Finding optimal move)
Let us combine what we have
learnt so far about minimax and evaluation function to write a proper
Tic-Tac-Toe AI (Artificial Intelligence) that plays a perfect game. This AI
will consider all possible scenarios and makes the most optimal move.
Finding
the Best Move :
We shall be introducing a
new function called findBestMove(). This function evaluates all the
available moves using minimax() and
then returns the best move the maximizer can make. The pseudocode is as follows
:
function findBestMove(board):
bestMove = NULL
for each move in board :
if current move is better than bestMove
bestMove = current move
return bestMove
Minimax
:
To check whether or not the
current move is better than the best move we take the help of minimax() function which will consider all the
possible ways the game can go and returns the best value for that move,
assuming the opponent also plays optimally
The code for the maximizer and minimizer in the minimax() function is similar to findBestMove() , the only difference is, instead of
returning a move, it will return a value. Here is the pseudocode :
function minimax(board, depth, isMaximizingPlayer):
if current board state is a terminal state :
return value of the board
if isMaximizingPlayer :
bestVal = -INFINITY
for each move in board :
value = minimax(board, depth+1, false)
bestVal = max( bestVal, value)
return bestVal
else :
bestVal = +INFINITY
for each move in board :
value = minimax(board, depth+1, true)
bestVal = min( bestVal, value)
return bestVal
Checking
for GameOver state :
To check whether the game
is over and to make sure there are no moves left we use isMovesLeft() function. It is a simple
straightforward function which checks whether a move is available or not and
returns true or false respectively. Pseudocode is as follows :
function isMovesLeft(board):
for each cell in board:
if current cell is empty:
return true
return false
Making
our AI smarter :
One final step is to make our AI a little bit smarter. Even though
the following AI plays perfectly, it might choose to make a move which will
result in a slower victory or a faster loss. Lets take an example and explain
it.
Assume that there are 2 possible ways for X to win the game from a
give board state.
§
Move A : X can win in 2 move
§
Move B : X can win in 4 moves
§
Our evaluation function
will return a value of +10 for both moves A and B. Even though
the move A is
better because it ensures a faster victory, our AI may choose B sometimes. To overcome this problem we
subtract the depth value from the evaluated score. This means that in case of a
victory it will choose a the victory which takes least number of moves and in
case of a loss it will try to prolong the game and play as many moves as
possible. So the new evaluated value will be
§
Move A will have a value of +10 – 2 = 8
§
Move B will have a value of +10 – 4 = 6
§
Now since move A has a higher score compared to move B our AI will choose move A over move B. The same
thing must be applied to the minimizer. Instead of subtracting the depth we add
the depth value as the minimizer always tries to get, as negative a value as
possible. We can subtract the depth either inside the evaluation function or
outside it. Anywhere is fine. I have chosen to do it outside the function.
Pseudocode implementation is as follows.
if maximizer has won:
return WIN_SCORE – depth
else if minimizer has won:
return LOOSE_SCORE +
depth
Outcome:
Output :
The value of the best Move is : 10
The Optimal Move is :
ROW: 2 COL: 2
This image depicts
all the possible paths that the game can take from the root board state. It is
often called the Game Tree.
The 3 possible scenarios in the above example are :
- Left Move: If X plays [2,0]. Then O will play [2,1] and
win the game. The value of this move is -10
- Middle Move: If X plays [2,1]. Then O will play [2,2] which
draws the game. The value of this move is 0
- Right Move: If X plays [2,2]. Then he will win the game.
The value of this move is +10;
Remember, even though X has a possibility of winning if he plays the
middle move, O will never let that happen and will choose to draw instead.
Therefore the best
choice for X, is to play [2,2], which will guarantee a victory for him.
Conclusion:













{kind=link}
{kind=link}
{kind=link}
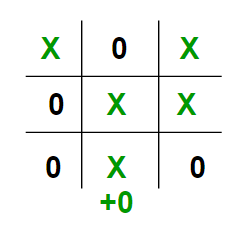{kind=link}
Comments
Post a Comment